一、CART树概述
CART树是典型的二叉树结构,在每个节点进行分类。
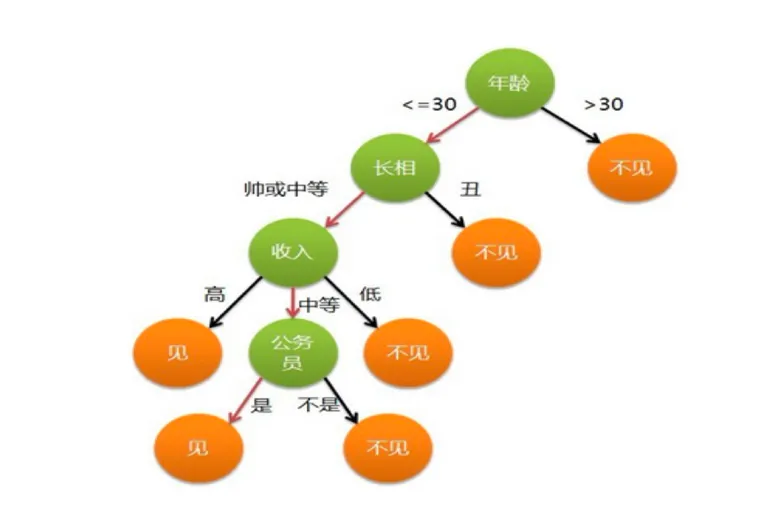
在CART树之前还有很多多叉决策树。树中每个内部节点表示一个特征上的判断,每个分支代表一个判断结果的输出,每个叶子节点代表一种分类结果。
CART可以实现回归和分类,在分类和回归的过程中分别使用基尼指数最小化策略和平方误差最小化策略。
二、基尼系数
2.1 含义
计算每个分类的概率的平方的总和。如节点中总共有两个分类各自占比 0.5:
$$
Gini(D) = 1 - (0.5^2) - (0.5^2) = 1 - 0.5 = 0.5
$$
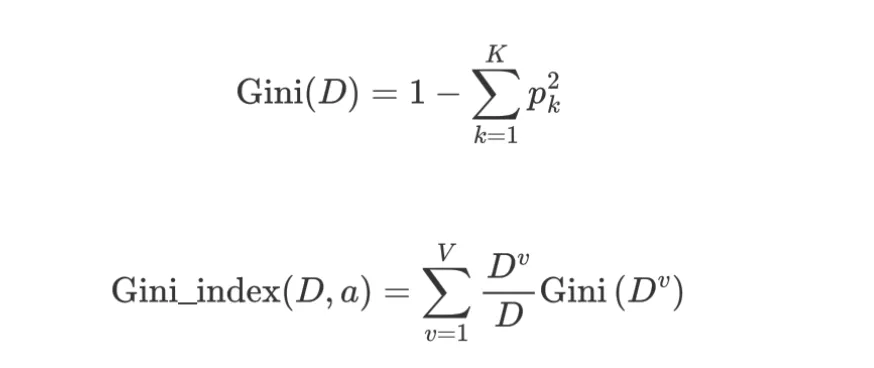
2.2 核心公式与物理意义
对于一个包含 K 个类别的数据集 D,设第 k 类样本在其中的占比为 $p_k$,则基尼不纯度:
$$
Gini(D) = 1 - \sum_{k=1}^{K} p_k^2
$$
直观物理意义:从该数据集中随机抽取 2 个样本,它们所属类别不一致的概率。
- 节点完全纯净时(所有样本同一类):$p_1 = 1$,其余为 0,$Gini(D) = 0$
- 节点完全混杂时(二分类各占 0.5):$Gini(D) = 1 - (0.5^2 + 0.5^2) = 0.5$(最大值)
基尼不纯度越小,代表该节点纯度越高,这正是决策树分裂时希望达成的目标。
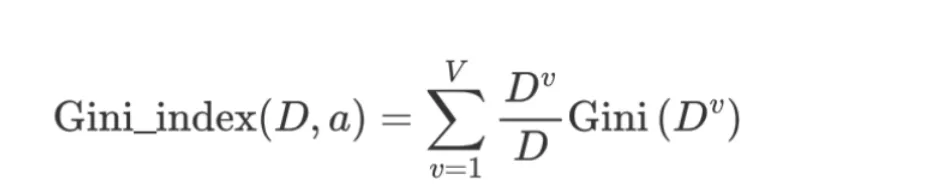
把该节点每个分类的基尼指数加权平均,分类的目标就是为了让这个集合最小。
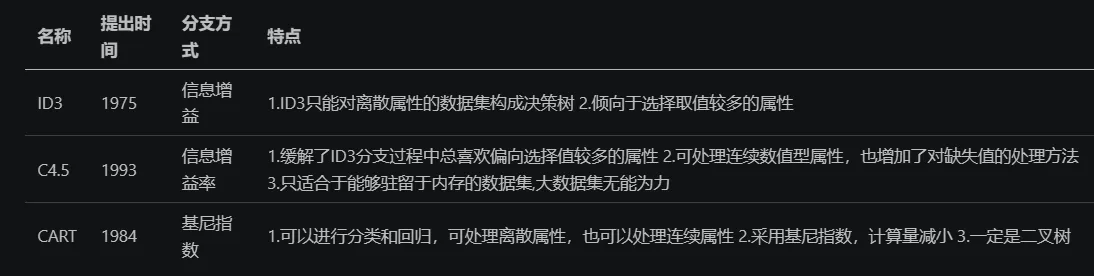
- 信息增益(ID3)、信息增益率(C4.5)值越大,优先选择该特征
- 基尼指数值越小(CART),优先选择该特征


CART算法确保 Gini 指数最低,也就是分类后同类的概率最大。
三、CART回归树
CART 回归树和 CART 分类树的不同之处:
- 分类树预测输出的是离散值,回归树预测输出的是连续值
- 分类树使用基尼指数作为划分依据,回归树使用平方损失
- 分类树用叶子节点里出现更多次数的类别作为预测,回归树则采用叶子节点里均值作为预测输出


让分类后两边更抱团——两边的平方误差直接算方差再加和,方差和越小越说明两边数据集中。
四、剪枝
剪枝是决策树对付过拟合的主要手段。决策树分支过多时会把训练集的噪声也学进去导致过拟合,通过主动去掉一些分支来降低风险。
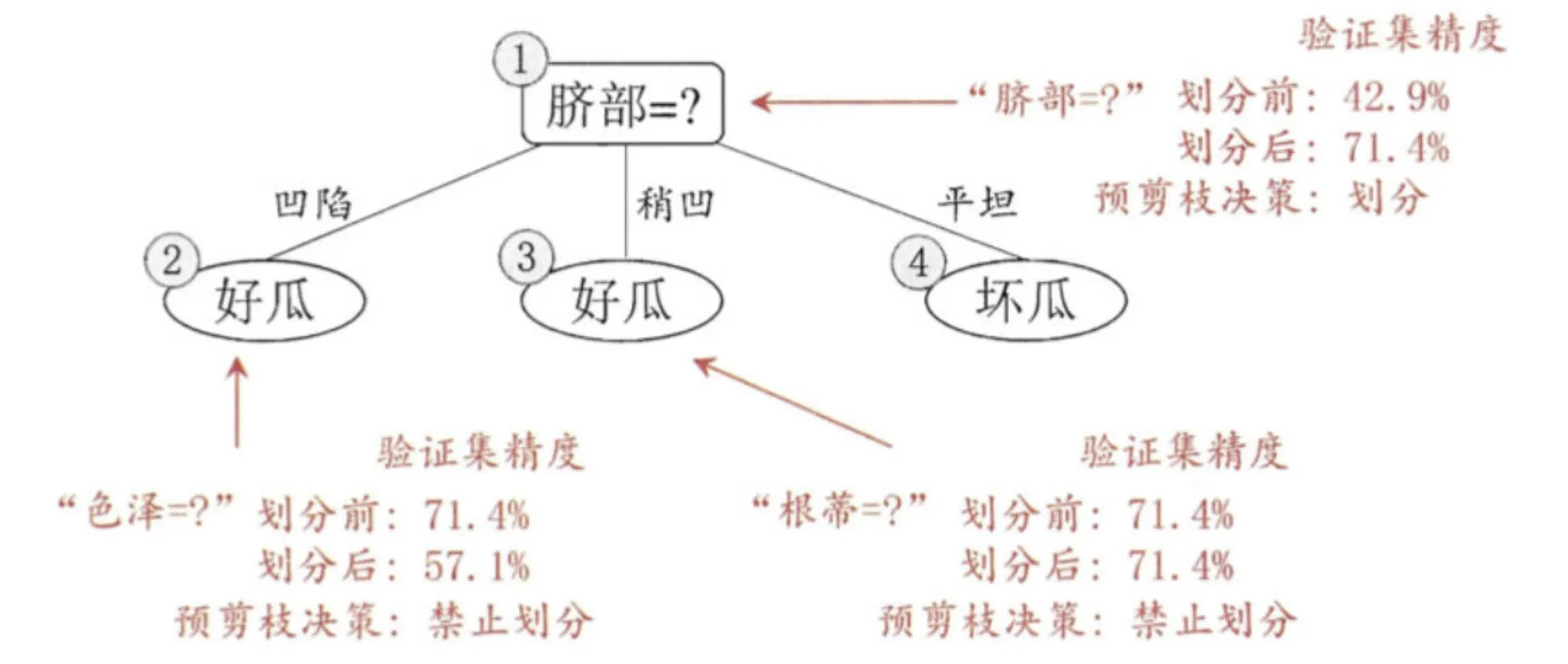
4.1 预剪枝 vs 后剪枝
| 维度 | 预剪枝 | 后剪枝(CCP) |
|---|---|---|
| 执行时机 | 树生长过程中,边生长边停止 | 树完全生长后,自底向上砍分支 |
| 核心逻辑 | 贪心判断单次分裂收益 | 全局评估子树性价比 |
| 计算成本 | 低,训练同步完成 | 高,需先生长完整树+交叉验证 |
| 泛化效果 | 一般,容易欠拟合 | 更好,结构更合理 |
| 短视风险 | 高,可能错过后续高收益分裂 | 无,基于完整树评估 |
| 工业使用频率 | 极高(集成学习标配) | 低,仅单棵树追求极致泛化时 |
4.2 预剪枝常用停止条件
| 停止条件 | 含义 |
|---|---|
max_depth |
树的深度达到阈值就停止分裂 |
min_samples_split |
当前节点样本数小于阈值就不再分裂 |
min_samples_leaf |
分裂后子节点样本数小于阈值就放弃 |
min_impurity_decrease |
分裂带来的增益小于阈值就不分裂 |
max_leaf_nodes |
叶子总数达到上限就停止生长 |
4.3 CART 标准方案:代价复杂度剪枝(CCP)
核心公式:
$$
C_\alpha(T) = C(T) + \alpha \cdot |T|
$$
- $C(T)$:整棵树的预测误差(分类用误分类数,回归用 SSE)
- $|T|$:树的叶子节点数量
- $\alpha$:正则化惩罚系数。$\alpha = 0$ 为完整大树,$\alpha$ 越大树越简单
两步法:
自底向上生成子树序列:从完整大树开始,每轮选择临界α最小的内部节点剪掉,得到一系列子树 $T_0, T_1, …, T_n$
交叉验证选择最优子树:用验证集测试每棵子树,选择验证误差最小的,若多个相近则选叶子更少的
4.4 工业落地建议
- 集成学习场景:几乎只用预剪枝,集成本身已通过多模型平均抑制过拟合
- 单棵CART树:追求最优泛化用CCP后剪枝,sklearn 通过
ccp_alpha参数开启 - 调参优先级:先调预剪枝参数快速收敛,如果单棵树还有过拟合空间再叠加 CCP